

Yale University vows to 'geolocate' most EJMR users [PART 2]
Yale University vows to 'geolocate' most EJMR users [PART 2]
they actually cracked the hash!!

Following my article this morning…
![Yale University vows to 'geolocate' most EJMR users [PART 1]](https://substackcdn.com/image/fetch/w_140,h_140,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fe2921848-687a-4d6f-bdf8-d07ba7ea4be0_1343x647.png)
… there is already a huge update!
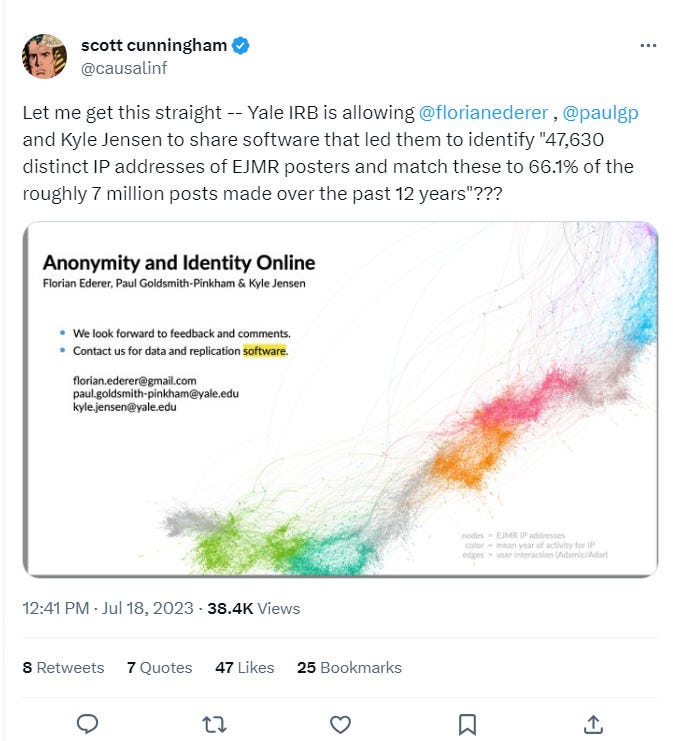
Roughly 30 minutes after my article was posted, Florian’s paper + slides leaked online, ahead his presentation in 2 days from now. Apparently, he posted this on his GitHub, and then deleted it, but somebody caught it and archived it. You can download the paper and slides here, don’t worry, this go-file hosting site is anonymous, or as anonymous as anything on the internet is (https://gofile.io/privacy):
There are 57 slides in Florian’s leaked NBER deck.


Long story short: it’s worse than most people thought.
They cracked the hash and obtained IPs of posters.
To recover IP addresses from the observed usernames on EJMR, we employ a multi-step procedure. First, we develop GPU-based software to quickly compute the SHA-1 hashes used for the username allocation algorithm on EJMR. In total, we compute almost 9 quadrillion hashes to fully enumerate all possible IP combinations and to check which of the resulting substrings of hashes match the observed usernames. For each post, this roughly narrows the set of possible IP addresses from 2 32 to 2 16. Second, we measure which IP addresses occur particularly often in a narrow time window and use the uniformity property of the SHA-1 hash to test whether these IP addresses appear more often than would likely occur by chance.


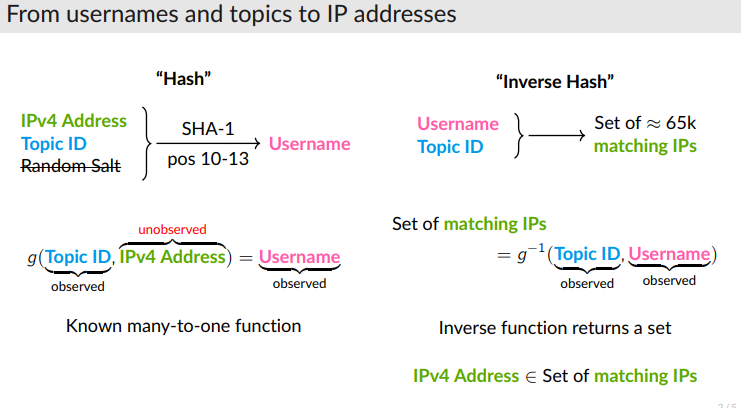
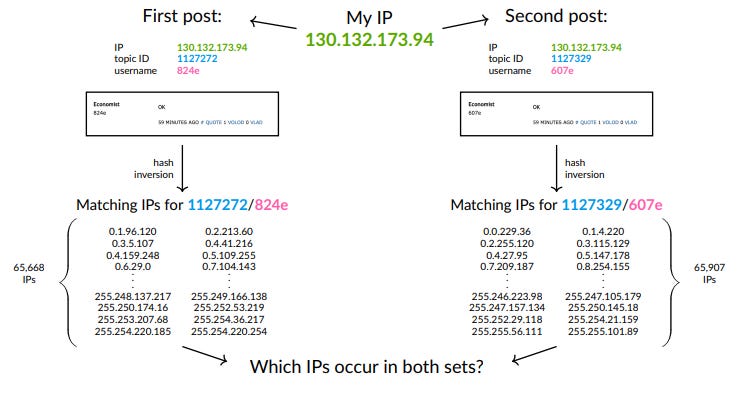
I am not going to pretend like I know the math, but I do know basic cybersecurity, and it seems like the big mistake that the site owner made was a pretty rookie cybersecurity mistake: he didn’t salt his hashes until... May 17, 2023, a few days after Florian announced the abstract.


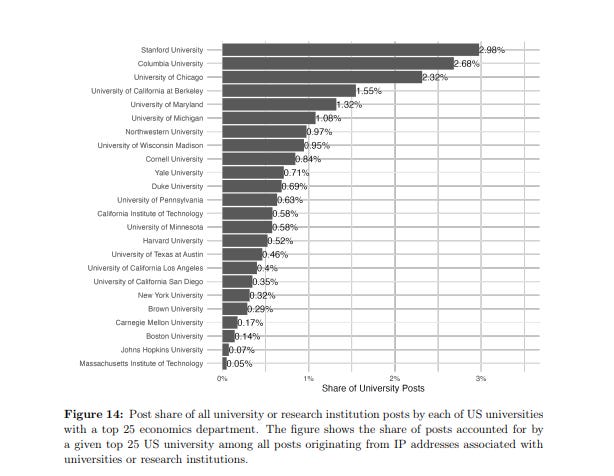
The paper does some cute NLP stuff, like, determine that Stanford and Columbia and Chicago are the most active departments on EJMR.
or that UCLA is the most “toxic” department:

The paper ends by identifying the IP address of EJMR’s anonymous owner, “Kirk”, who once, bragged that nobody could ever identify him.
Is that a legally binding million-dollar contract?

This IP address is in Leeds, UK.
This is Kirk’s answer:


The leaked slides/paper has just started going viral on Twitter, the first grumblings are starting to come out, soon it will be huge. The most notable tweet so far is Scott Cunningham, professor of economics at Baylor University, who is extremely pissed:
Here are some first impressions:
I post from Erdogan's Turkey and count myself dead already. Thank you for ruining our tiny window of freedom Florian.
— Anonymous
Possibly content based regulation by IRB’s? If IRB’s like the probable result, they apply a lower standard. Not the first time this has happened.
—Anup Malani , law prof at University of Chicago
Doxxing is apparently legal in economics research....
— Aleksandra Klofat, data scientist
"This study was determined to be exempt by the Yale University IRB, protocol 2000034072."
Very serious organization right here.
I do not think HHS will agree.
https://www.hhs.gov/ohrp/compliance-and-reporting/submitting-a-complaint/index.html
— Anonymous
My wife has depression and I have posted about the difficulties that this has caused me. I posted late at night, unable to sleep, and I presumed that was anonymous. It would be very embarrassing if my personal posts were identifiable.
If FE has posted a method to identify me, and my wife, then that is deeply unethical.
— Anonymous
You can undo the sha-1 yourself easily, everyone can replicate. No need for "code and data". All IPs will be public momentarily.
— Anonymous
The clever thing to do is a class action.
— Anonymous
The Ederer paper is illegal
They've scraped a website with intent to harm and doxx the users as well as to harm the website.
There have been cases where scrapers have done very similar actions and been charged.
— Anonymous
UCLA in da House!
— Anonymous
Yep. This was malfeasance. While there is no expectation of privacy in public, there is an expectation of privacy in spaces with clearly articulated privacy policies (like private clubs). Kirk, please kill hash here and sjrm.
I also want to report to Yale and tell them I'll be contacting my attorney.
— Anonymous
I have never posted anything on here that id defamatory or toxic, but I was extremely worried that this paper would reveal intimate personal details that I disclosed on this page anonymously. I will be talking to a lawyer next week to discuss what I can do about the distress that FE and his ridiculous twitter campaign caused for me over the past few weeks.
— Anonymous
Meh, most ISPs use dynamic IPs. Your IP is “loaned” to you for sometime and then you get a new one from time to time. Just unplug and plug back your modem. You’ll see.
Plus, your ISP maintains logs going not more than 6 months back, and the relevant reason for sharing your ID is not “Florian told me to.”
Complete failure of a paper. And, lol at this getting leaked 2 days before. Seems like Florian can’t even get this right.
— Anonymous
Who did people think was posting on EJMR if not Econ PhDs?
— Stan Veuger, AIE senior fellow
Yale IRB also should not have approved the study. I think what they did is clearly a violation of IRB guidelines because it puts users at risk.
— Anonymous
They have the technique. And they explained it. Doesn’t matter what they do or do not do. It’s now out there and will be done. It cost them $8000 to run this on university servers.
— Anonymous
I skimmed the paper and the slides. There is no contribution to economics in the paper, but the effect on past EJMR posters will be huge. They describe the hashing (and “unhashing”) procedure. Anyone who posted in two or more threads from the same IP is screwed.
ID doesn't dox, it takes the detective work by linking posts across threads. When you know a person has inside info about 2 specific departments, knows a ton about a certain class of macro models, and also speaks Portugese, then you are revealed.
— Anonymous
If my comments on EJMR defending the honor of Sociology are identified, I will personally sue.
— Tim Gill, Assistant Professor Department of Sociology, University of Georgia
My prediction is this method can get used in civil court and they will be paid as expert witnesses and make millions.
— Anonymous
The code and data will obviously come with strings attached, like not Doxxing specific individuals. But anyone with intro-CS level skills and some hustle ability can redo their procedure and not be bound by any constraints on anything.
— Anonymous
This is such a nothingburger paper. PGP and FE wanted to piss off the profession with this sloppily done paper? Remarkable.
— Anonymous
Why are people calling this paper a nothing burger? They show that out of the millions of posts that they assign to ay pees, less than one would have been assigned to a wrong ay pee. So again, why is this a nothing burger?
— Anonymous
Kirk, As the site owner, you should contact the Yale IRB. You definitely have standing as the analysis could impact your business. You can also attest to the site’s privacy policy firsthand.
— Anonymous
Ederer's approach is fundamentally flawed Assume that you have ten posts in ten threads such that there is only one possible IP that matches all of them. This exists for sure. But we don't know in advance that these ten posts are linked together.
What you can do: Find for every post a set of possible IPs and see if some of these IPs appear more than once. Or find some public IPs (from universities) which fits to these IPs. But this is more like guessing.
— Anonymous
Then they may have misrepresented the study to the Yale IRB. Studies that are greater than minimal risk do not qualify for exemption. Even if the data is only public data but it provides for more than minimal risk, then it should not be exempted from IRB review.
— Anonymous
The authors do not directly mention any IPs except for Kirk’s, but anyone with a bit of resources can easily rerun their analysis and uncover all those IPs. It’s probably a matter of weeks, maybe even days from now.
For people in Europe, you should not be too worried. GDPR does not allow ISPs and universities to store certain types of IT information for long time-periods. European universities will not be able to link a specific device to an IP, even if they wanted to.
If you are in the US, there are also some data retention limits. Your ISP will not be able to reveal which one of their customers used exactly what IP several years ago.
There is a very very small group of people that may have to worry.
1) you posted frequently so that FE can do their little brute force math trick
2) you posted from the same IP when you posted frequently (not one post from home, one post on your phone from the subway, and one post at your office)
3) you posted frequently within a short period of time (most IPs are dynamic, they change even if you use the same device)
4) you broke some law that will lay the groundwork for a subpoena etc
5) someone with legal standing for a specific post of yours decides to spend the time and money to get the subpoena (without knowing if they will succeed)
6) your interpret provider (ISP or university) actually still has the data the subpoena requests.
Now calculate a product of the small probabilities of each of these aspects. For the vast majority of us the resulting number is 0.
— Anonymous
This is just heating up….
Expect the MSM to cover this any minute now….
Scott is a good dude, and not just because of his excellent mixtapes.
Lazy or ignorant techs leave big holes. Good thing the Internet isn't forever....OOPS!